Algorithme Java pour normaliser l'audio
J'essaie de normaliser un fichier audio de la parole.
Plus précisément, lorsqu'un fichier audio contient des pics de volume, j'essaie de le niveler, de sorte que les sections silencieuses sont plus fortes et les pics sont plus silencieux.
Je sais très peu de choses sur la manipulation audio, au-delà de ce que j'ai appris en travaillant sur cette tâche. Aussi, mon calcul est trop faible.
J'ai fait quelques recherches, et le site Xuggle fournit un exemple qui montre la réduction du volume en utilisant le code suivant: (version complète ici)
@Override
public void onAudioSamples(IAudioSamplesEvent event)
{
// get the raw audio byes and adjust it's value
ShortBuffer buffer = event.getAudioSamples().getByteBuffer().asShortBuffer();
for (int i = 0; i < buffer.limit(); ++i)
buffer.put(i, (short)(buffer.get(i) * mVolume));
super.onAudioSamples(event);
}
Ici, ils modifier les octets getAudioSamples() par une constante de mVolume.
En s'appuyant sur cette approche, j'ai tenté une normalisation qui modifie les octets dans getAudioSamples() en une valeur normalisée, en tenant compte du max/min dans le fichier. (Voir ci-dessous pour plus de détails). J'ai un filtre simple pour laisser" silence " seul (ie., tout ce qui est inférieur à une valeur).
Je suis la recherche que le fichier de sortie est très bruyant (ie. la qualité est sérieusement dégradée). Je suppose que l'erreur est soit dans mon algorithme de normalisation, soit dans la façon dont je manipule les octets. Cependant, je ne sais pas où aller ensuite.
Voici une version abrégée de ce que je fais actuellement.
Étape 1: Trouver les pics dans le fichier:
Lit le fichier audio complet et trouve les valeurs les plus élevées et les plus basses de buffer.get() pour tous les AudioSamples
@Override
public void onAudioSamples(IAudioSamplesEvent event) {
IAudioSamples audioSamples = event.getAudioSamples();
ShortBuffer buffer =
audioSamples.getByteBuffer().asShortBuffer();
short min = Short.MAX_VALUE;
short max = Short.MIN_VALUE;
for (int i = 0; i < buffer.limit(); ++i) {
short value = buffer.get(i);
min = (short) Math.min(min, value);
max = (short) Math.max(max, value);
}
// assign of min/max ommitted for brevity.
super.onAudioSamples(event);
}
Étape 2: Normaliser toutes les valeurs:
Dans une boucle similaire à step1, remplacez le tampon par des valeurs normalisées, appel:
buffer.put(i, normalize(buffer.get(i));
public short normalize(short value) {
if (isBackgroundNoise(value))
return value;
short rawMin = // min from step1
short rawMax = // max from step1
short targetRangeMin = 1000;
short targetRangeMax = 8000;
int abs = Math.abs(value);
double a = (abs - rawMin) * (targetRangeMax - targetRangeMin);
double b = (rawMax - rawMin);
double result = targetRangeMin + ( a/b );
// Copy the sign of value to result.
result = Math.copySign(result,value);
return (short) result;
}
Questions:
- Est-ce une approche valide pour tenter de normaliser un fichier audio?
- Mon calcul dans
normalize()est-il valide? - Pourquoi cela rendrait-il le fichier bruyant, alors qu'une approche similaire dans le code de démonstration ne le fait pas?
2 answers
Je ne pense pas que le concept de "valeur minimale de l'échantillon" soit très significatif, car la valeur de l'échantillon représente simplement la "hauteur" actuelle de l'onde sonore à un certain instant. C'est-à-dire que sa valeur absolue variera entre la valeur de crête du clip audio et zéro. Ainsi, avoir un targetRangeMin semble être faux et provoquera probablement une distorsion de la forme d'onde.
Je pense qu'une meilleure approche pourrait être d'avoir une sorte de fonction de poids qui diminue la valeur de l'échantillon en fonction de sa taille. C'est-à-dire que les valeurs plus grandes sont diminuées d'un pourcentage élevé par rapport aux valeurs plus petites. Cela introduirait également une certaine distorsion, mais probablement pas très perceptible.
Edit: voici un exemple d'implémentation d'une telle méthode:
public short normalize(short value) {
short rawMax = // max from step1
short targetMax = 8000;
//This is the maximum volume reduction
double maxReduce = 1 - targetMax/(double)rawMax;
int abs = Math.abs(value);
double factor = (maxReduce * abs/(double)rawMax);
return (short) Math.round((1 - factor) * value);
}
Pour référence, voici ce que votre algorithme a fait à une courbe sinusoïdale avec une amplitude de 10000: 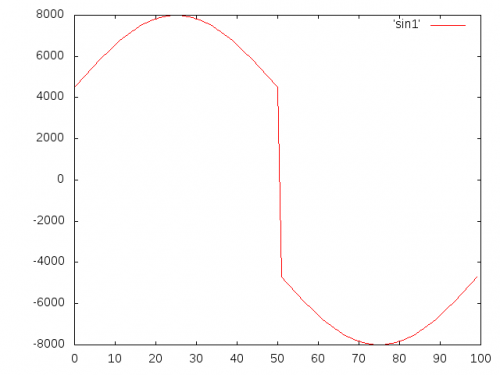
Ceci explique pourquoi la qualité audio devient bien pire après avoir été normalisée.
C'est le résultat après l'exécution avec mon {[2 suggéré]} méthode: 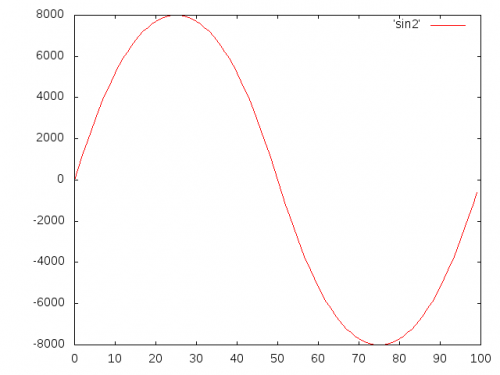
La"normalisation" de l'audio est le processus d'augmentation du niveau de l'audio de telle sorte que le maximum soit égal à une valeur donnée, généralement la valeur maximale possible. Aujourd'hui, dans une autre question, quelqu'un a expliqué comment procéder (voir #1): normalisation du volume audio
Cependant, vous continuez à dire "Spécifiquement, lorsqu'un fichier audio contient des pics de volume, j'essaie de le niveler, donc les sections silencieuses sont plus fortes et les pics sont plus silencieux."Ce qui est appelé "compression" ou "limiter" (à ne pas confondre avec le type de compression tel que celui utilisé dans l'encodage MP3s!). Vous pouvez en savoir plus à ce sujet ici: http://en.wikipedia.org/wiki/Dynamic_range_compression
Un compresseur simple n'est pas particulièrement difficile à mettre en œuvre, mais vous dites que votre calcul "est embarrassant."Donc, vous voudrez peut-être en trouver un qui est déjà construit. Vous pourriez être en mesure de trouver un compresseur implémenté dans http://sox.sourceforge.net / et convertissez cela de C en Java. La seule implémentation java de compressor que je connaisse est disponible (et ce n'est pas très bon) dans ce livre
Comme alternative pour résoudre votre problème, vous pourrez peut-être normaliser votre fichier en segments de disons 1/2 seconde chacun, puis connecter les valeurs de gain que vous utilisez pour chaque segment en utilisant l'interpolation linéaire. Vous pouvez lire sur l'interpolation linéaire pour l'audio ici: http://blog.bjornroche.com/2010/10/linear-interpolation-for-audio-in-c-c.html
Je ne sais pas si le code source est disponible pour le levelator, mais c'est autre chose que vous pouvez essayer.