Pourquoi Java switch on contiguous ints semble-t-il fonctionner plus rapidement avec des cas ajoutés?
Je travaille sur du code Java qui doit être hautement optimisé car il fonctionnera dans des fonctions chaudes qui sont invoquées à de nombreux points de la logique de mon programme principal. Une partie de ce code consiste à multiplier double variables par 10 élevé à arbitraire non négatif int exponents. Un moyen rapide (edit: mais pas le plus rapide possible, voir la mise à jour 2 ci-dessous) pour obtenir la valeur multipliée est de switch sur le exponent:
double multiplyByPowerOfTen(final double d, final int exponent) {
switch (exponent) {
case 0:
return d;
case 1:
return d*10;
case 2:
return d*100;
// ... same pattern
case 9:
return d*1000000000;
case 10:
return d*10000000000L;
// ... same pattern with long literals
case 18:
return d*1000000000000000000L;
default:
throw new ParseException("Unhandled power of ten " + power, 0);
}
}
Les ellipses commentées ci-dessus indiquent que le case int les constantes continuent d'incrémenter de 1, il y a donc vraiment 19 cases dans l'extrait de code ci-dessus. Comme je ne savais pas si j'aurais réellement besoin de toutes les puissances de 10 dans les instructions case 10 thru 18, j'ai exécuté quelques microbenchmarks comparant le temps nécessaire pour terminer 10 millions d'opérations avec cette instruction switch par rapport à un switch avec seulement cases 0 thru 9 (avec le exponent limité à 9 ou moins pour éviter J'ai eu le plutôt surprenant (pour moi, au moins!) résultat le switch plus long avec plus d'instructions case s'exécutait en fait plus rapidement.
Sur une alouette, j'ai essayé d'ajouter encore plus de casequi ont juste renvoyé des valeurs factices, et j'ai trouvé que je pouvais faire fonctionner le commutateur encore plus rapidement avec environ 22-27 case déclarés (même si ces cas factices ne sont jamais réellement touchés pendant que le code est en cours d'exécution). (Encore une fois, cases ont été ajoutés de manière contiguë en incrémentant la constante précédente case par 1.) Ces différences de temps d'exécution ne sont pas très significatives: pour un au hasard exponent entre 0 et 10, l'instruction dummy rembourré switch termine 10 millions d'exécutions en 1,49 seconde contre 1,54 seconde pour la version non rembourrée, pour une économie totale de 5ns par exécution. Donc, ce n'est pas le genre de chose qui rend obsédé par le remplissage d'une instruction switch qui en vaut la peine du point de vue de l'optimisation. Mais je trouve toujours curieux et contre-intuitif qu'un switch ne devienne pas plus lent (ou peut-être au mieux maintenir un O(1) temps constant) pour exécuter car plus de case y sont ajoutés.
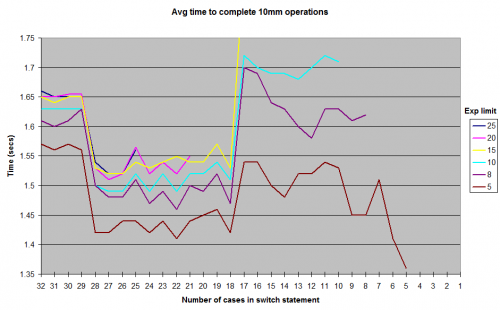
Ce sont les résultats que j'ai obtenus en exécutant avec diverses limites sur les valeurs exponent générées aléatoirement. Je n'ai pas inclus les résultats jusqu'à 1 pour la limite exponent, mais la forme générale de la courbe reste la même, avec une crête autour de la marque de cas 12-17, et une vallée entre 18-28. Tous les tests ont été exécutés dans JUnitBenchmarks à l'aide de conteneurs partagés pour les valeurs aléatoires afin de garantir des tests identiques entrée. J'ai également exécuté les tests à la fois dans l'ordre de l'instruction la plus longue switch à la plus courte, et vice-versa, pour essayer d'éliminer la possibilité de problèmes de test liés à l'ordre. J'ai mis mon code de test sur un dépôt github si quelqu'un veut essayer de reproduire ces résultats.
Alors, que se passe-t-il ici? Quelques aléas de mon architecture ou micro-benchmark construction? Ou est la Java switch vraiment un peu plus rapide à s'exécuter dans le 18 pour 28 case que c'est à partir de 11 jusqu'à 17?
Le repo de test Github "switch-experiment"
MISE À JOUR: J'ai nettoyé un peu la bibliothèque de benchmarking et ajouté un fichier texte dans /results avec une sortie sur un plus large éventail de valeurs exponent possibles. J'ai également ajouté une option dans le code de test pour ne pas lancer un Exception à partir de default, mais cela ne semble pas affecter les résultats.
MISE À JOUR 2: A trouvé une assez bonne discussion de cette question à partir de 2009 sur le forum xkcd ici: http://forums.xkcd.com/viewtopic.php?f=11&t=33524 . La discussion de l'OP sur l'utilisation de Array.binarySearch() m'a donné l'idée d'une implémentation simple basée sur un tableau du modèle d'exponentiation ci-dessus. Il n'y a pas besoin de la recherche binaire puisque je sais quelles sont les entrées dans le array. Il semble environ 3 fois plus rapide qu'à l'aide de switch, évidemment au détriment d'une partie du flux de contrôle switch offre. Ce code a également été ajouté au dépôt github.
4 answers
Comme indiqué par l'autre réponse, parce que les valeurs de casse sont contiguës (par opposition à clairsemées), le bytecode généré pour vos différents tests utilise une table de commutation (instruction bytecode tableswitch).
Cependant, une fois que le JIT démarre son travail et compile le bytecode en assembly, l'instruction tableswitch n'entraîne pas toujours un tableau de pointeurs: parfois la table de commutation est transformée en ce qui ressemble à un lookupswitch (similaire à un if / else if structure).
Décompiler l'assembly généré par le JIT (hotspot JDK 1.7) montre qu'il utilise une succession de if/else if quand il y a 17 cas ou moins, un tableau de pointeurs quand il y en a plus de 18 (plus efficace).
La raison pour laquelle ce nombre magique de 18 est utilisé semble se résumer à la valeur par défaut du MinJumpTableSize Drapeau JVM (autour de la ligne 352 dans le code).
J'ai soulevé le problème sur la liste du compilateur hotspot et il semble être un héritage des tests passés. Notez que cette valeur par défaut a été supprimée dans JDK 8après plus de benchmarking a été effectué.
Enfin, lorsque la méthode devient trop longue (> 25 cas dans mes tests), elle n'est plus intégrée aux paramètres JVM par défaut - c'est la cause la plus probable de la baisse des performances à ce stade.
Avec 5 cas, le code décompilé ressemble à ceci (notez les instructions cmp/je/jg/jmp, l'assemblage pour si/goto):
[Verified Entry Point]
# {method} 'multiplyByPowerOfTen' '(DI)D' in 'javaapplication4/Test1'
# parm0: xmm0:xmm0 = double
# parm1: rdx = int
# [sp+0x20] (sp of caller)
0x00000000024f0160: mov DWORD PTR [rsp-0x6000],eax
; {no_reloc}
0x00000000024f0167: push rbp
0x00000000024f0168: sub rsp,0x10 ;*synchronization entry
; - javaapplication4.Test1::multiplyByPowerOfTen@-1 (line 56)
0x00000000024f016c: cmp edx,0x3
0x00000000024f016f: je 0x00000000024f01c3
0x00000000024f0171: cmp edx,0x3
0x00000000024f0174: jg 0x00000000024f01a5
0x00000000024f0176: cmp edx,0x1
0x00000000024f0179: je 0x00000000024f019b
0x00000000024f017b: cmp edx,0x1
0x00000000024f017e: jg 0x00000000024f0191
0x00000000024f0180: test edx,edx
0x00000000024f0182: je 0x00000000024f01cb
0x00000000024f0184: mov ebp,edx
0x00000000024f0186: mov edx,0x17
0x00000000024f018b: call 0x00000000024c90a0 ; OopMap{off=48}
;*new ; - javaapplication4.Test1::multiplyByPowerOfTen@72 (line 83)
; {runtime_call}
0x00000000024f0190: int3 ;*new ; - javaapplication4.Test1::multiplyByPowerOfTen@72 (line 83)
0x00000000024f0191: mulsd xmm0,QWORD PTR [rip+0xffffffffffffffa7] # 0x00000000024f0140
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@52 (line 62)
; {section_word}
0x00000000024f0199: jmp 0x00000000024f01cb
0x00000000024f019b: mulsd xmm0,QWORD PTR [rip+0xffffffffffffff8d] # 0x00000000024f0130
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@46 (line 60)
; {section_word}
0x00000000024f01a3: jmp 0x00000000024f01cb
0x00000000024f01a5: cmp edx,0x5
0x00000000024f01a8: je 0x00000000024f01b9
0x00000000024f01aa: cmp edx,0x5
0x00000000024f01ad: jg 0x00000000024f0184 ;*tableswitch
; - javaapplication4.Test1::multiplyByPowerOfTen@1 (line 56)
0x00000000024f01af: mulsd xmm0,QWORD PTR [rip+0xffffffffffffff81] # 0x00000000024f0138
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@64 (line 66)
; {section_word}
0x00000000024f01b7: jmp 0x00000000024f01cb
0x00000000024f01b9: mulsd xmm0,QWORD PTR [rip+0xffffffffffffff67] # 0x00000000024f0128
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@70 (line 68)
; {section_word}
0x00000000024f01c1: jmp 0x00000000024f01cb
0x00000000024f01c3: mulsd xmm0,QWORD PTR [rip+0xffffffffffffff55] # 0x00000000024f0120
;*tableswitch
; - javaapplication4.Test1::multiplyByPowerOfTen@1 (line 56)
; {section_word}
0x00000000024f01cb: add rsp,0x10
0x00000000024f01cf: pop rbp
0x00000000024f01d0: test DWORD PTR [rip+0xfffffffffdf3fe2a],eax # 0x0000000000430000
; {poll_return}
0x00000000024f01d6: ret
Avec 18 cas, l'assemblage ressemble à ceci (notez le tableau de pointeurs qui est utilisé et supprime le besoin de toutes les comparaisons: jmp QWORD PTR [r8+r10*1] saute directement à la bonne multiplication) - c'est la raison probable de l'amélioration des performances:
[Verified Entry Point]
# {method} 'multiplyByPowerOfTen' '(DI)D' in 'javaapplication4/Test1'
# parm0: xmm0:xmm0 = double
# parm1: rdx = int
# [sp+0x20] (sp of caller)
0x000000000287fe20: mov DWORD PTR [rsp-0x6000],eax
; {no_reloc}
0x000000000287fe27: push rbp
0x000000000287fe28: sub rsp,0x10 ;*synchronization entry
; - javaapplication4.Test1::multiplyByPowerOfTen@-1 (line 56)
0x000000000287fe2c: cmp edx,0x13
0x000000000287fe2f: jae 0x000000000287fe46
0x000000000287fe31: movsxd r10,edx
0x000000000287fe34: shl r10,0x3
0x000000000287fe38: movabs r8,0x287fd70 ; {section_word}
0x000000000287fe42: jmp QWORD PTR [r8+r10*1] ;*tableswitch
; - javaapplication4.Test1::multiplyByPowerOfTen@1 (line 56)
0x000000000287fe46: mov ebp,edx
0x000000000287fe48: mov edx,0x31
0x000000000287fe4d: xchg ax,ax
0x000000000287fe4f: call 0x00000000028590a0 ; OopMap{off=52}
;*new ; - javaapplication4.Test1::multiplyByPowerOfTen@202 (line 96)
; {runtime_call}
0x000000000287fe54: int3 ;*new ; - javaapplication4.Test1::multiplyByPowerOfTen@202 (line 96)
0x000000000287fe55: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe8b] # 0x000000000287fce8
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@194 (line 92)
; {section_word}
0x000000000287fe5d: jmp 0x000000000287ff16
0x000000000287fe62: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe86] # 0x000000000287fcf0
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@188 (line 90)
; {section_word}
0x000000000287fe6a: jmp 0x000000000287ff16
0x000000000287fe6f: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe81] # 0x000000000287fcf8
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@182 (line 88)
; {section_word}
0x000000000287fe77: jmp 0x000000000287ff16
0x000000000287fe7c: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe7c] # 0x000000000287fd00
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@176 (line 86)
; {section_word}
0x000000000287fe84: jmp 0x000000000287ff16
0x000000000287fe89: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe77] # 0x000000000287fd08
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@170 (line 84)
; {section_word}
0x000000000287fe91: jmp 0x000000000287ff16
0x000000000287fe96: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe72] # 0x000000000287fd10
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@164 (line 82)
; {section_word}
0x000000000287fe9e: jmp 0x000000000287ff16
0x000000000287fea0: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe70] # 0x000000000287fd18
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@158 (line 80)
; {section_word}
0x000000000287fea8: jmp 0x000000000287ff16
0x000000000287feaa: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe6e] # 0x000000000287fd20
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@152 (line 78)
; {section_word}
0x000000000287feb2: jmp 0x000000000287ff16
0x000000000287feb4: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe24] # 0x000000000287fce0
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@146 (line 76)
; {section_word}
0x000000000287febc: jmp 0x000000000287ff16
0x000000000287febe: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe6a] # 0x000000000287fd30
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@140 (line 74)
; {section_word}
0x000000000287fec6: jmp 0x000000000287ff16
0x000000000287fec8: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe68] # 0x000000000287fd38
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@134 (line 72)
; {section_word}
0x000000000287fed0: jmp 0x000000000287ff16
0x000000000287fed2: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe66] # 0x000000000287fd40
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@128 (line 70)
; {section_word}
0x000000000287feda: jmp 0x000000000287ff16
0x000000000287fedc: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe64] # 0x000000000287fd48
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@122 (line 68)
; {section_word}
0x000000000287fee4: jmp 0x000000000287ff16
0x000000000287fee6: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe62] # 0x000000000287fd50
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@116 (line 66)
; {section_word}
0x000000000287feee: jmp 0x000000000287ff16
0x000000000287fef0: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe60] # 0x000000000287fd58
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@110 (line 64)
; {section_word}
0x000000000287fef8: jmp 0x000000000287ff16
0x000000000287fefa: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe5e] # 0x000000000287fd60
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@104 (line 62)
; {section_word}
0x000000000287ff02: jmp 0x000000000287ff16
0x000000000287ff04: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe5c] # 0x000000000287fd68
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@98 (line 60)
; {section_word}
0x000000000287ff0c: jmp 0x000000000287ff16
0x000000000287ff0e: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe12] # 0x000000000287fd28
;*tableswitch
; - javaapplication4.Test1::multiplyByPowerOfTen@1 (line 56)
; {section_word}
0x000000000287ff16: add rsp,0x10
0x000000000287ff1a: pop rbp
0x000000000287ff1b: test DWORD PTR [rip+0xfffffffffd9b00df],eax # 0x0000000000230000
; {poll_return}
0x000000000287ff21: ret
Et enfin l'assemblage avec 30 cas (ci-dessous) ressemble à 18 cas, à l'exception du movapd xmm0,xmm1 supplémentaire qui apparaît vers le milieu du code, comme repéré par @cHao - cependant le la raison la plus probable de la baisse des performances est que la méthode est trop longue pour être alignée avec les paramètres JVM par défaut:
[Verified Entry Point]
# {method} 'multiplyByPowerOfTen' '(DI)D' in 'javaapplication4/Test1'
# parm0: xmm0:xmm0 = double
# parm1: rdx = int
# [sp+0x20] (sp of caller)
0x0000000002524560: mov DWORD PTR [rsp-0x6000],eax
; {no_reloc}
0x0000000002524567: push rbp
0x0000000002524568: sub rsp,0x10 ;*synchronization entry
; - javaapplication4.Test1::multiplyByPowerOfTen@-1 (line 56)
0x000000000252456c: movapd xmm1,xmm0
0x0000000002524570: cmp edx,0x1f
0x0000000002524573: jae 0x0000000002524592 ;*tableswitch
; - javaapplication4.Test1::multiplyByPowerOfTen@1 (line 56)
0x0000000002524575: movsxd r10,edx
0x0000000002524578: shl r10,0x3
0x000000000252457c: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe3c] # 0x00000000025243c0
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@364 (line 118)
; {section_word}
0x0000000002524584: movabs r8,0x2524450 ; {section_word}
0x000000000252458e: jmp QWORD PTR [r8+r10*1] ;*tableswitch
; - javaapplication4.Test1::multiplyByPowerOfTen@1 (line 56)
0x0000000002524592: mov ebp,edx
0x0000000002524594: mov edx,0x31
0x0000000002524599: xchg ax,ax
0x000000000252459b: call 0x00000000024f90a0 ; OopMap{off=64}
;*new ; - javaapplication4.Test1::multiplyByPowerOfTen@370 (line 120)
; {runtime_call}
0x00000000025245a0: int3 ;*new ; - javaapplication4.Test1::multiplyByPowerOfTen@370 (line 120)
0x00000000025245a1: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe27] # 0x00000000025243d0
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@358 (line 116)
; {section_word}
0x00000000025245a9: jmp 0x0000000002524744
0x00000000025245ae: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe22] # 0x00000000025243d8
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@348 (line 114)
; {section_word}
0x00000000025245b6: jmp 0x0000000002524744
0x00000000025245bb: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe1d] # 0x00000000025243e0
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@338 (line 112)
; {section_word}
0x00000000025245c3: jmp 0x0000000002524744
0x00000000025245c8: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe18] # 0x00000000025243e8
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@328 (line 110)
; {section_word}
0x00000000025245d0: jmp 0x0000000002524744
0x00000000025245d5: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe13] # 0x00000000025243f0
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@318 (line 108)
; {section_word}
0x00000000025245dd: jmp 0x0000000002524744
0x00000000025245e2: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe0e] # 0x00000000025243f8
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@308 (line 106)
; {section_word}
0x00000000025245ea: jmp 0x0000000002524744
0x00000000025245ef: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe09] # 0x0000000002524400
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@298 (line 104)
; {section_word}
0x00000000025245f7: jmp 0x0000000002524744
0x00000000025245fc: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe04] # 0x0000000002524408
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@288 (line 102)
; {section_word}
0x0000000002524604: jmp 0x0000000002524744
0x0000000002524609: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffdff] # 0x0000000002524410
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@278 (line 100)
; {section_word}
0x0000000002524611: jmp 0x0000000002524744
0x0000000002524616: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffdfa] # 0x0000000002524418
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@268 (line 98)
; {section_word}
0x000000000252461e: jmp 0x0000000002524744
0x0000000002524623: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffd9d] # 0x00000000025243c8
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@258 (line 96)
; {section_word}
0x000000000252462b: jmp 0x0000000002524744
0x0000000002524630: movapd xmm0,xmm1
0x0000000002524634: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe0c] # 0x0000000002524448
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@242 (line 92)
; {section_word}
0x000000000252463c: jmp 0x0000000002524744
0x0000000002524641: movapd xmm0,xmm1
0x0000000002524645: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffddb] # 0x0000000002524428
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@236 (line 90)
; {section_word}
0x000000000252464d: jmp 0x0000000002524744
0x0000000002524652: movapd xmm0,xmm1
0x0000000002524656: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffdd2] # 0x0000000002524430
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@230 (line 88)
; {section_word}
0x000000000252465e: jmp 0x0000000002524744
0x0000000002524663: movapd xmm0,xmm1
0x0000000002524667: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffdc9] # 0x0000000002524438
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@224 (line 86)
; {section_word}
[etc.]
0x0000000002524744: add rsp,0x10
0x0000000002524748: pop rbp
0x0000000002524749: test DWORD PTR [rip+0xfffffffffde1b8b1],eax # 0x0000000000340000
; {poll_return}
0x000000000252474f: ret
Switch - case est plus rapide si les valeurs de casse sont placées dans une plage étroite, par exemple.
case 1:
case 2:
case 3:
..
..
case n:
Parce que, dans ce cas, le compilateur peut éviter d'effectuer une comparaison pour chaque segment de cas dans l'instruction switch. Le compilateur fait une table de saut qui contient les adresses des actions à effectuer sur différentes jambes. La valeur sur laquelle le commutateur est effectué est manipulée pour la convertir en un index dans le jump table. Dans cette implémentation, le temps pris dans le commutateur l'instruction est beaucoup moins longue que le temps pris dans une cascade d'instruction if-else-if équivalente. Aussi le temps pris dans l'instruction switch est indépendant du nombre de cas de jambes en l'instruction switch.
Comme indiqué dans wikipedia à propos de switch statement dans la section Compilation.
Si la plage de valeurs d'entrée est identifiable "petite" et n'a quelques lacunes, certains compilateurs qui intègrent un optimiseur peut effectivement implémentez l'instruction switch en tant que branch table ou un tableau de pointeurs de fonction indexés au lieu d'une longue série de instruction. Cela permet à l'instruction switch de déterminer instantanément quelle branche exécuter sans avoir à passer par une liste de comparaison.
La réponse se trouve dans le bytecode:
SwitchTest10.java
public class SwitchTest10 {
public static void main(String[] args) {
int n = 0;
switcher(n);
}
public static void switcher(int n) {
switch(n) {
case 0: System.out.println(0);
break;
case 1: System.out.println(1);
break;
case 2: System.out.println(2);
break;
case 3: System.out.println(3);
break;
case 4: System.out.println(4);
break;
case 5: System.out.println(5);
break;
case 6: System.out.println(6);
break;
case 7: System.out.println(7);
break;
case 8: System.out.println(8);
break;
case 9: System.out.println(9);
break;
case 10: System.out.println(10);
break;
default: System.out.println("test");
}
}
}
Bytecode correspondant; seules les parties pertinentes montrées:
public static void switcher(int);
Code:
0: iload_0
1: tableswitch{ //0 to 10
0: 60;
1: 70;
2: 80;
3: 90;
4: 100;
5: 110;
6: 120;
7: 131;
8: 142;
9: 153;
10: 164;
default: 175 }
SwitchTest22.java:
public class SwitchTest22 {
public static void main(String[] args) {
int n = 0;
switcher(n);
}
public static void switcher(int n) {
switch(n) {
case 0: System.out.println(0);
break;
case 1: System.out.println(1);
break;
case 2: System.out.println(2);
break;
case 3: System.out.println(3);
break;
case 4: System.out.println(4);
break;
case 5: System.out.println(5);
break;
case 6: System.out.println(6);
break;
case 7: System.out.println(7);
break;
case 8: System.out.println(8);
break;
case 9: System.out.println(9);
break;
case 100: System.out.println(10);
break;
case 110: System.out.println(10);
break;
case 120: System.out.println(10);
break;
case 130: System.out.println(10);
break;
case 140: System.out.println(10);
break;
case 150: System.out.println(10);
break;
case 160: System.out.println(10);
break;
case 170: System.out.println(10);
break;
case 180: System.out.println(10);
break;
case 190: System.out.println(10);
break;
case 200: System.out.println(10);
break;
case 210: System.out.println(10);
break;
case 220: System.out.println(10);
break;
default: System.out.println("test");
}
}
}
Bytecode correspondant; encore une fois, seules les parties pertinentes montrées:
public static void switcher(int);
Code:
0: iload_0
1: lookupswitch{ //23
0: 196;
1: 206;
2: 216;
3: 226;
4: 236;
5: 246;
6: 256;
7: 267;
8: 278;
9: 289;
100: 300;
110: 311;
120: 322;
130: 333;
140: 344;
150: 355;
160: 366;
170: 377;
180: 388;
190: 399;
200: 410;
210: 421;
220: 432;
default: 443 }
Dans le premier cas, avec des plages étroites, le bytecode compilé utilise un tableswitch. Dans le second cas, le code compilé utilise un lookupswitch.
Dans tableswitch, l'entier la valeur en haut de la pile est utilisée pour indexer dans la table, pour trouver la cible de branche/saut. Ce saut / branche est alors effectué immédiatement. Par conséquent, il s'agit d'une opération O(1).
Un lookupswitch est plus compliqué. Dans ce cas, la valeur entière doit être comparée à toutes les clés de la table jusqu'à ce que la clé correcte soit trouvée. Une fois la clé trouvée, la cible de branche/saut (à laquelle cette clé est mappée) est utilisée pour le saut. La table utilisée dans lookupswitch est triée et une recherche binaire l'algorithme peut être utilisé pour trouver la bonne clé. Les performances pour une recherche binaire sont O(log n), et l'ensemble du processus est également O(log n), car le saut est toujours O(1). Donc, la raison pour laquelle les performances sont inférieures dans le cas de plages clairsemées est que la clé correcte doit d'abord être recherchée car vous ne pouvez pas indexer directement dans la table.
S'il y a des valeurs clairsemées et que vous n'aviez qu'un tableswitch à utiliser, la table contiendrait essentiellement des entrées fictives qui pointent vers l'option default. Exemple, en supposant que la dernière entrée dans SwitchTest10.java est 21 au lieu de 10, on obtient:
public static void switcher(int);
Code:
0: iload_0
1: tableswitch{ //0 to 21
0: 104;
1: 114;
2: 124;
3: 134;
4: 144;
5: 154;
6: 164;
7: 175;
8: 186;
9: 197;
10: 219;
11: 219;
12: 219;
13: 219;
14: 219;
15: 219;
16: 219;
17: 219;
18: 219;
19: 219;
20: 219;
21: 208;
default: 219 }
Donc, le compilateur crée essentiellement cette énorme table contenant des entrées factices entre les espaces, pointant vers la cible de la branche de l'instruction default. Même s'il n'y a pas de default, il contiendra des entrées pointant vers l'instruction après le bloc de commutation. J'ai fait quelques tests de base, et j'ai trouvé que si l'écart entre la dernière et l'indice précédent (9) est supérieure à 35, il utilise un lookupswitch au lieu de tableswitch.
Le comportement de la switch énoncé est défini dans Java Virtual Machine Spécification (§3.10):
Lorsque les cas du commutateur sont rares, la représentation en table de l'instruction tableswitch devient inefficace en termes d'espace. L'instruction lookupswitch peut être utilisée à la place. L'instruction lookupswitch associe les clés int (les valeurs des étiquettes de casse) aux décalages cibles dans une table. Quand un lookupswitch l'instruction est exécutée, la valeur de l'expression du commutateur est comparée aux clés de la table. Si l'une des clés correspond à la valeur de l'expression, l'exécution se poursuit au décalage cible associé. Si aucune clé ne correspond, l'exécution se poursuit sur la cible par défaut. [...]
Puisque la question est déjà répondue (plus ou moins), voici quelques conseils. Utiliser
private static final double[] mul={1d, 10d...};
static double multiplyByPowerOfTen(final double d, final int exponent) {
if (exponent<0 || exponent>=mul.length) throw new ParseException();//or just leave the IOOBE be
return mul[exponent]*d;
}
Ce code utilise beaucoup moins d'IC (cache d'instructions) et sera toujours en ligne. Le tableau sera dans le cache de données L1 si le code est chaud. La table de recherche est presque toujours une victoire. (esp. sur microbenchmarks: D)
Edit: si vous souhaitez que la méthode soit en ligne à chaud, considérez les chemins non rapides comme {[1] } comme aussi courts que le minimum ou déplacez-les vers une méthode statique distincte (ce qui les rend court comme minimum). C'est - à-dire que throw new ParseException("Unhandled power of ten " + power, 0); est une idée faible b/c il mange beaucoup du budget d'inlining pour le code qui peut être simplement interprété-la concaténation de chaînes est assez verbeuse en bytecode . Plus d'infos et un cas réel avec ArrayList