In che modo una HashMap Java gestisce oggetti diversi con lo stesso codice hash?
Secondo la mia comprensione penso:
- È perfettamente legale che due oggetti abbiano lo stesso hashcode.
- Se due oggetti sono uguali (usando il metodo equals ()) allora hanno lo stesso hashcode.
- Se due oggetti non sono uguali allora non possono avere lo stesso hashcode
Ho ragione?
Ora se sono corretto, ho la seguente domanda:
Il HashMap utilizza internamente l'hashcode dell'oggetto. Quindi se due oggetti possono avere lo stesso hashcode, allora come può HashMap tracciare quale chiave usa?
Qualcuno può spiegare come il HashMap utilizza internamente l'hashcode dell'oggetto?
16 answers
Una hashmap funziona così (questo è un po ' semplificato, ma illustra il meccanismo di base):
Ha un numero di "bucket" che utilizza per memorizzare coppie chiave-valore. Ogni bucket ha un numero univoco-questo è ciò che identifica il bucket. Quando si inserisce una coppia chiave-valore nella mappa, hashmap esaminerà il codice hash della chiave e memorizzerà la coppia nel bucket di cui l'identificatore è il codice hash della chiave. Ad esempio: Il codice hash della chiave è 235- > la coppia è memorizzato nel secchio numero 235. (Si noti che un bucket può memorizzare più di una coppia chiave-valore).
Quando cerchi un valore nella hashmap, dandogli una chiave, guarderà prima il codice hash della chiave che hai dato. L'hashmap esaminerà quindi il bucket corrispondente e quindi confronterà la chiave che hai dato con le chiavi di tutte le coppie nel bucket, confrontandole con equals().
Ora puoi vedere come questo è molto efficiente per cercare coppie chiave-valore in a mappa: con il codice hash della chiave hashmap sa immediatamente in quale bucket guardare, in modo che debba solo testare ciò che è in quel bucket.
Guardando il meccanismo di cui sopra, puoi anche vedere quali requisiti sono necessari sui metodi di chiavi hashCode() e equals():
Se due chiavi sono uguali (
equals()restituiscetruequando le confronti), il loro metodohashCode()deve restituire lo stesso numero. Se le chiavi violano questo, le chiavi uguali potrebbero essere memorizzate in bucket e hashmap non sarebbe in grado di trovare coppie chiave-valore (perché guarderà nello stesso bucket).Se due chiavi sono diverse, non importa se i loro codici hash sono uguali o meno. Saranno memorizzati nello stesso bucket se i loro codici hash sono gli stessi, e in questo caso, la hashmap utilizzerà
equals()per distinguerli.
La tua terza affermazione non è corretta.
È perfettamente legale che due oggetti disuguali abbiano lo stesso codice hash. Viene utilizzato da HashMap come "filtro primo passaggio" in modo che la mappa possa trovare rapidamente possibili voci con la chiave specificata. Le chiavi con lo stesso codice hash vengono quindi testate per l'uguaglianza con la chiave specificata.
Non vorresti un requisito che due oggetti disuguali non potessero avere lo stesso codice hash, altrimenti ciò ti limiterebbe a 232 oggetti possibili. (Significherebbe anche che tipi diversi non potrebbero nemmeno utilizzare i campi di un oggetto per generare codici hash, poiché altre classi potrebbero generare lo stesso hash.)
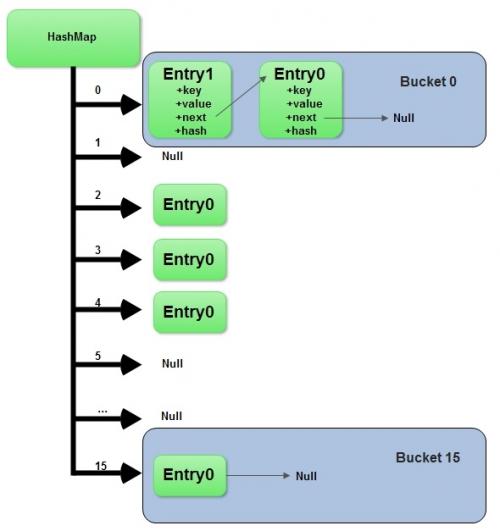
HashMap è una matrice di oggetti Entry.
Considera HashMap come un semplice array di oggetti.
Dai un'occhiata a cosa è questo Object:
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
final int hash;
…
}
Ogni oggetto Entry rappresenta una coppia chiave-valore. Il campo next fa riferimento a un altro oggetto Entry se un bucket ha più di un Entry.
A volte potrebbe accadere che i codici hash per 2 oggetti diversi siano gli stessi. In questo caso, due oggetti verranno salvati in un bucket e verranno presentati come elenco collegato.
Il punto di ingresso è l'oggetto aggiunto più di recente. Questo oggetto fa riferimento a un altro oggetto con il campo next e così via. L'ultima voce si riferisce a null.
Quando si crea un HashMap con il costruttore predefinito
HashMap hashMap = new HashMap();
L'array viene creato con la dimensione 16 e il bilanciamento del carico predefinito 0.75.
Aggiunta di una nuova coppia chiave-valore
- Calcola hashcode per la chiave
- Calcola la posizione
hash % (arrayLength-1)in cui l'elemento deve essere posizionato (bucket numero) - Se si tenta di aggiungere un valore con una chiave che è già stata salvata in
HashMap, il valore viene sovrascritto. - Altrimenti l'elemento viene aggiunto al bucket.
Se il bucket ha già almeno un elemento, ne viene aggiunto uno nuovo e posizionato nella prima posizione del bucket. Il suo campo next si riferisce al vecchio elemento.
Cancellazione
- Calcola hashcode per la chiave data
- Calcola il numero del bucket
hash % (arrayLength-1) - Ottieni un riferimento al primo oggetto Entry nel bucket e mediante il metodo equals iterare su tutte le voci nel bucket specificato. Alla fine troveremo il corretto
Entry. Se non viene trovato un elemento desiderato, restituirenull
Puoi trovare informazioni eccellenti su http://javarevisited.blogspot.com/2011/02/how-hashmap-works-in-java.html
Per riassumere:
HashMap funziona sul principio di hashing
Put (key, value): HashMap memorizza sia l'oggetto chiave che il valore come mappa.Entrata. Hashmap applica hashcode (chiave) per ottenere il bucket. se c'è collisione ,HashMap utilizza LinkedList per memorizzare l'oggetto.
Get (key): HashMap utilizza l'hashcode dell'oggetto Chiave per trovare out bucket posizione e quindi chiamare i tasti.metodo equals () per identificare il nodo corretto in LinkedList e restituire l'oggetto valore associato per quella chiave in Java HashMap.
Ecco una descrizione approssimativa del meccanismo di HashMap, per la versione Java 8, (potrebbe essere leggermente diverso da Java 6) .
Strutture dati
-
Tabella hash
Il valore hash viene calcolato tramitehash()sulla chiave e decide quale bucket della hashtable utilizzare per una determinata chiave. -
Elenco collegato (singolarmente)
Quando il conteggio degli elementi in un bucket è piccolo, un elenco collegato singolarmente è utilizzare. -
Albero rosso-Nero
Quando il conteggio degli elementi in un secchio è grande, viene utilizzato un albero rosso-nero.
Classi (interne)
-
Map.Entry
Rappresenta una singola entità nella mappa, l'entità chiave / valore. -
HashMap.Node
Versione dell'elenco collegato del nodo.Potrebbe rappresentare:
- Un secchio di hash.
Perché ha una proprietà hash. - Un nodo nell'elenco collegato singolarmente, (quindi anche capo di linkedlist) .
- Un secchio di hash.
-
HashMap.TreeNode
Versione ad albero del nodo.
Campi (interno)
-
Node[] table
La tabella bucket, (capo delle liste collegate).
Se un bucket non contiene elementi, allora è nullo, quindi occupa solo lo spazio di un riferimento. -
Set<Map.Entry> entrySetInsieme di entità. -
int size
Numero di entità. -
float loadFactor
Indicare quanto è consentita la tabella hash completa, prima ridimensionare. -
int threshold
La dimensione successiva alla quale ridimensionare.
Formula:threshold = capacity * loadFactor
Metodi (interno)
-
int hash(key)
Calcola hash per chiave. -
Come mappare l'hash al bucket?
Usa la seguente logica:static int hashToBucket(int tableSize, int hash) { return (tableSize - 1) & hash; }
Circa la capacità
Nella tabella hash, la capacità indica il conteggio del bucket, potrebbe essere ottenuto da table.length.
Inoltre potrebbe essere calcolato tramite threshold e loadFactor, quindi non c'è bisogno di essere definito come un campo di classe.
Potrebbe ottenere la capacità effettiva tramite: capacity()
Operazioni
- Trova l'entità per chiave.
Per prima cosa trova il bucket in base al valore hash, quindi fai un ciclo elenco collegato o cerca albero ordinato. - Aggiungi entità con chiave.
Prima trova il bucket in base al valore hash della chiave.
Quindi prova a trovare il valore:- Se trovato, sostituire il valore.
- In caso contrario, aggiungere un nuovo nodo all'inizio dell'elenco collegato, o inserire nell'albero ordinato.
- Ridimensiona
Quandothresholdraggiunto, raddoppierà la capacità di hashtable (table.length), quindi eseguire un re-hash su tutti gli elementi per ricostruire la tabella.
Questa potrebbe essere un'operazione costosa.
Prestazioni
- ottieni e metti
La complessità temporale èO(1), perché:- Il bucket
- è accessibile tramite l'indice dell'array, quindi
O(1). - L'elenco collegato in ogni bucket è di piccola lunghezza, quindi potrebbe essere visualizzato come
O(1).
Anche la dimensione dell'albero - è limitata, perché estenderà la capacità e il re-hash quando il conteggio degli elementi aumenta, quindi potrebbe vederlo come
O(1), nonO(log N).
- è accessibile tramite l'indice dell'array, quindi
L'hashcode determina quale bucket per la hashmap controllare. Se c'è più di un oggetto nel bucket, viene eseguita una ricerca lineare per trovare quale elemento nel bucket è uguale all'elemento desiderato (usando il metodo equals()).
In altre parole, se hai un hashcode perfetto, l'accesso hashmap è costante, non dovrai mai scorrere un bucket (tecnicamente dovresti anche avere bucket MAX_INT, l'implementazione Java potrebbe condividere alcuni codici hash nello stesso bucket per ridurre i requisiti di spazio). Se hai il peggior hashcode (restituisce sempre lo stesso numero), l'accesso hashmap diventa lineare poiché devi cercare ogni elemento nella mappa (sono tutti nello stesso bucket) per ottenere ciò che vuoi.
La maggior parte delle volte un hashcode ben scritto non è perfetto ma è abbastanza unico da darti un accesso più o meno costante.
Ti sbagli sul punto tre. Due voci possono avere lo stesso codice hash ma non essere uguali. Dai un'occhiata all'implementazione di HashMap.ottieni da OpenJDK. Puoi vedere che controlla che gli hash siano uguali e che le chiavi siano uguali. Se il punto tre fosse vero, non sarebbe necessario verificare che le chiavi siano uguali. Il codice hash viene confrontato prima della chiave perché il primo è un confronto più efficiente.
Se sei interessato a imparare un po ' di più a proposito di questo, dai un'occhiata all'articolo di Wikipedia su Open Addressing collision resolution, che credo sia il meccanismo utilizzato dall'implementazione OpenJDK. Questo meccanismo è sottilmente diverso dall'approccio" bucket " che una delle altre risposte menziona.
Questa è una domanda molto confusa per molti di noi nelle interviste.Ma non è così complesso.
Sappiamo
-
HashMap memorizza coppia chiave-valore nella mappa.Ingresso (lo sappiamo tutti)
-
HashMap funziona su algoritmo di hashing e utilizza hashCode() e equals() metodo in put() e get() metodi. (anche noi lo sappiamo)
When we call put method by passing key-value pair, HashMap uses Key **hashCode()** with hashing to **find out the index** to store the key-value pair. (this is important)The Entry is **stored in the LinkedList**, so if there are already existing entry, it uses **equals() method to check if the passed key already exists** (even this is important)Se sì sovrascrive il valore altrimenti crea una nuova voce e memorizza questa voce chiave-valore.
-
Quando chiamiamo get method passando la chiave, di nuovo usa hashCode() per trovare l'indice nell'array e quindi usa equals() metodo per trovare la voce corretta e restituirne il valore. (ora questo è ovvio)
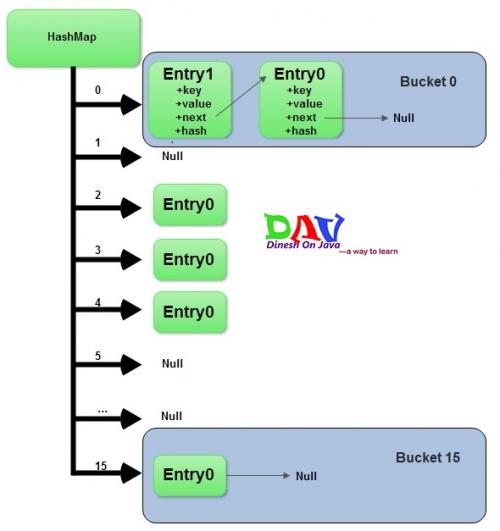
QUESTA IMMAGINE TI AIUTERÀ A CAPIRE:
Modifica settembre 2017: qui vediamo come il valore hash se usato insieme a equals dopo averlo trovato secchio.
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
}
import java.util.HashMap;
public class Students {
String name;
int age;
Students(String name, int age ){
this.name = name;
this.age=age;
}
@Override
public int hashCode() {
System.out.println("__hash__");
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
System.out.println("__eq__");
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Students other = (Students) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
public static void main(String[] args) {
Students S1 = new Students("taj",22);
Students S2 = new Students("taj",21);
System.out.println(S1.hashCode());
System.out.println(S2.hashCode());
HashMap<Students,String > HM = new HashMap<Students,String > ();
HM.put(S1, "tajinder");
HM.put(S2, "tajinder");
System.out.println(HM.size());
}
}
Output:
__ hash __
116232
__ hash __
116201
__ hash __
__ hash __
2
Quindi qui vediamo che se entrambi gli oggetti S1 e S2 hanno contenuti diversi, allora siamo abbastanza sicuri che il nostro metodo Hashcode sovrascritto genererà Hashcode diverso(116232,11601) per entrambi gli oggetti. ORA, dal momento che ci sono diversi codici hash, quindi non si preoccuperà nemmeno di chiamare il metodo EQUALS. Perché un Hashcode diverso GARANTISCE contenuti DIVERSI in un oggetto.
public static void main(String[] args) {
Students S1 = new Students("taj",21);
Students S2 = new Students("taj",21);
System.out.println(S1.hashCode());
System.out.println(S2.hashCode());
HashMap<Students,String > HM = new HashMap<Students,String > ();
HM.put(S1, "tajinder");
HM.put(S2, "tajinder");
System.out.println(HM.size());
}
}
Now lets change out main method a little bit. Output after this change is
__ hash __
116201
__ hash __
116201
__ hash __
__ hash __
__ eq __
1
We can clearly see that equal method is called. Here is print statement __eq__, since we have same hashcode, then content of objects MAY or MAY not be similar. So program internally calls Equal method to verify this.
Conclusion
If hashcode is different , equal method will not get called.
if hashcode is same, equal method will get called.
Thanks , hope it helps.
Hash map funziona sul principio di hashing
Il metodo HashMap get(Key k) chiama il metodo hashCode sull'oggetto key e applica hashValue restituito alla propria funzione hash statica per trovare una posizione bucket(backing array) in cui chiavi e valori sono memorizzati sotto forma di una classe nidificata chiamata Entry (Map.Entrata) . Quindi hai concluso che dalla riga precedente sia la chiave che il valore sono memorizzati nel bucket come una forma di oggetto Entry . Quindi pensando che solo il valore sia memorizzato nel bucket non è corretto e non darà una buona impressione sull'intervistatore .
- Ogni volta che chiamiamo il metodo get( Key k ) sull'oggetto HashMap . Innanzitutto controlla se la chiave è null o meno . Si noti che ci può essere solo una chiave null in HashMap .
Se la chiave è null, le chiavi Null mappano sempre all'hash 0, quindi all'indice 0.
Se key non è null , chiamerà hashfunction sull'oggetto key , vedere la riga 4 nel metodo precedente, ovvero key.hashCode (), quindi dopo la chiave.hashCode() restituisce hashValue, la riga 4 assomiglia a
int hash = hash(hashValue)
E ora ,applica hashValue restituito nella propria funzione di hashing .
Potremmo chiederci perché stiamo calcolando di nuovo hashvalue usando hash(hashValue). La risposta è che difende dalle funzioni hash di scarsa qualità.
Ora final hashvalue viene utilizzato per trovare la posizione del bucket in cui è memorizzato l'oggetto Entry . L'oggetto Entry memorizza nel bucket in questo modo (hash,key,value,bucketindex)
Ogni oggetto Entry rappresenta la coppia chiave-valore. Il campo next si riferisce ad un altro oggetto Entry se un bucket ha più di 1 Entry.
A volte potrebbe accadere che gli HASHCODE per 2 oggetti diversi siano gli stessi. In questo caso 2 oggetti verranno salvati in un bucket e verranno presentati come LinkedList. Il punto di ingresso è più recentemente aggiunto oggetto. Questo oggetto si riferisce ad un altro oggetto con il campo successivo e quindi uno. L'ultima voce si riferisce a null. Quando si crea HashMap con default costruttore
Array viene creato con la dimensione 16 e il bilanciamento del carico predefinito 0.75.
Non entrerò nei dettagli di come funziona HashMap, ma fornirò un esempio in modo che possiamo ricordare come funziona HashMap mettendolo in relazione con la realtà.
Abbiamo Chiave, Valore ,HashCode e bucket.
Per qualche tempo, metteremo in relazione ciascuno di essi con il seguente:
- Secchio- > Una società
- HashCode - > Indirizzo della società (unico sempre)
- Valore- > Una casa nella società
- Chiave - > Indirizzo di casa.
Utilizzando la mappa.ottieni (chiave) :
Stevie vuole arrivare alla casa del suo amico (Josse) che vive in una villa in una società VIP, lascia che sia la società JavaLovers. L'indirizzo di Josse è il suo SSN (che è diverso per tutti). C'è un indice mantenuto in cui scopriamo il nome della Società basato su SSN. Questo indice può essere considerato un algoritmo per scoprire l'HashCode.
- Nome della Società SSN
- 92313 (Josse) Jav JavaLovers
- 13214 Ang AngularJSLovers
- 98080 -- JavaLovers
- 53808 Bi BiologyLovers
- Questo SSN(chiave) prima ci dà un HashCode(dalla tabella degli indici) che non è altro che il nome della Società.
- Ora, le case multiple possono essere nella stessa società, quindi l'HashCode può essere comune.
- Supponiamo che la Società sia comune per due case, come identificheremo quale casa andremo, sì, usando la chiave (SSN) che non è altro che l'indirizzo della Casa
Utilizzando Mappa.put (chiave, Valore)
Questo trova una società adatta per questo valore trovando l'HashCode e quindi il valore viene memorizzato.
Spero che questo aiuti e questo sia aperto alle modifiche.
In una forma estatizzata di Come funziona hashMap in java?
HashMap funziona sul principio di hashing, abbiamo messo() e get() metodo per la memorizzazione e il recupero di oggetti da HashMap. Quando passiamo sia la chiave che il valore al metodo put () da memorizzare su HashMap, utilizza il metodo key object hashcode () per calcolare l'hashcode e applicando l'hash su quell'hashcode, identifica la posizione del bucket per la memorizzazione dell'oggetto value. Durante il recupero, utilizza il metodo key object equals per scoprirlo coppia di valori chiave corretta e oggetto valore restituito associato a tale chiave. HashMap utilizza la lista collegata in caso di collisione e l'oggetto verrà memorizzato nel prossimo nodo della lista collegata. Anche HashMap memorizza sia tupla chiave + valore in ogni nodo della lista collegata.
Due oggetti sono uguali, implica che hanno lo stesso hashcode, ma non viceversa
Aggiornamento Java 8 in HashMap -
Fai questa operazione nel tuo codice -
myHashmap.put("old","key-value-pair");
myHashMap.put("very-old","old-key-value-pair");
Quindi, supponiamo che il tuo hashcode restituito per entrambe le chiavi "old" e "very-old" sia lo stesso. Allora cosa succederà.
myHashMap è una HashMap e supponiamo che inizialmente non sia stata specificata la sua capacità. Quindi la capacità predefinita secondo java è 16. Quindi ora non appena hai inizializzato hashmap utilizzando la nuova parola chiave, ha creato 16 bucket. ora quando hai eseguito la prima istruzione -
myHashmap.put("old","key-value-pair");
Quindi viene calcolato l'hashcode per "old", e poiché l'hashcode potrebbe essere anche un numero intero molto grande, quindi java lo ha fatto internamente - (hash è hashcode qui e > > > è shift destro)
hash XOR hash >>> 16
Quindi per dare un'immagine più grandeit restituirà un indice, che sarebbe compreso tra 0 e 15. Ora la coppia di valori chiave "old" e {[10] } verrà convertita nell'istanza chiave e valore dell'oggetto Entry variabile. e poi questo oggetto entry verrà memorizzato nel bucket, oppure puoi dire che in un particolare indice, questo oggetto entry verrà memorizzato.
FYI - Entry è una classe in Map interface - Map.Voce, con queste firma / definizione
class Entry{
final Key k;
value v;
final int hash;
Entry next;
}
Ora quando si esegue l'istruzione successiva -
myHashmap.put("very-old","old-key-value-pair");
E "very-old" fornisce lo stesso hashcode di "old", quindi questa nuova coppia di valori chiave viene nuovamente inviata allo stesso indice o allo stesso bucket. Ma poiché questo secchio non è vuoto, allora il next la variabile dell'oggetto Entry viene utilizzata per memorizzare questa nuova coppia di valori chiave.
E questo verrà memorizzato come elenco collegato per ogni oggetto che ha lo stesso hashcode, ma viene specificato un TRIEFY_THRESHOLD con valore 6. quindi, dopo questo raggiunge, la lista collegata viene convertita nell'albero bilanciato(albero rosso-nero) con il primo elemento come radice.
Come si dice, un'immagine vale 1000 parole. Dico: un codice è meglio di 1000 parole. Ecco il codice sorgente di HashMap. Ottieni metodo:
/**
* Implements Map.get and related methods
*
* @param hash hash for key
* @param key the key
* @return the node, or null if none
*/
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
Quindi diventa chiaro che hash viene utilizzato per trovare il "bucket" e il primo elemento viene sempre controllato in quel bucket. In caso contrario, equals della chiave viene utilizzato per trovare l'elemento effettivo nell'elenco collegato.
Vediamo il metodo put():
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
È leggermente più complicato, ma diventa chiaro che il nuovo elemento è inserisci la scheda nella posizione calcolata in base all'hash:
i = (n - 1) & hash qui i è l'indice in cui verrà inserito il nuovo elemento (o è il "bucket"). n è la dimensione dell'array tab (array di "bucket").
In primo luogo, si cerca di essere messo come il primo elemento di in quel "secchio". Se è già presente un elemento, aggiungere un nuovo nodo all'elenco.
Sarà una risposta lunga, prendi un drink e continua a leggere {
L'hashing consiste nel memorizzare una coppia chiave-valore in memoria che può essere letta e scritta più velocemente. Memorizza le chiavi in un array e i valori in un LinkedList .
Diciamo che voglio memorizzare 4 coppie di valori chiave -
{
“girl” => “ahhan” ,
“misused” => “Manmohan Singh” ,
“horsemints” => “guess what”,
“no” => “way”
}
Quindi per memorizzare le chiavi abbiamo bisogno di una matrice di 4 elementi . Ora come faccio a mappare una di queste 4 chiavi a 4 indici di array (0,1,2,3)?
Quindi java trova l'hashCode delle singole chiavi e mapparli a un particolare indice di array . Le formule Hashcode sono -
1) reverse the string.
2) keep on multiplying ascii of each character with increasing power of 31 . then add the components .
3) So hashCode() of girl would be –(ascii values of l,r,i,g are 108, 114, 105 and 103) .
e.g. girl = 108 * 31^0 + 114 * 31^1 + 105 * 31^2 + 103 * 31^3 = 3173020
Hash e ragazza !! So cosa stai pensando. Il tuo fascino per quel duetto selvaggio potrebbe farti perdere una cosa importante .
Perché java moltiplicarlo con 31 ?
È perché, 31 è un primo dispari nella forma 2^5 - 1 . E odd prime riduce la possibilità di collisione Hash
Ora come questo codice hash è mappato su un array indice?
La risposta è , Hash Code % (Array length -1) . Quindi “girl” è mappato su (3173020 % 3) = 1 nel nostro caso . che è il secondo elemento dell'array .
E il valore "ahhan" è memorizzato in un LinkedList associato all'indice array 1 .
HashCollision - Se provi a trovare hasHCode delle chiavi “misused” e “horsemints” usando le formule sopra descritte vedrai che entrambi ci danno lo stesso 1069518484. Whooaa !! lezione appresa -
2 oggetti uguali devono avere lo stesso hashCode ma lì è alcuna garanzia se l'hashCode corrisponde quindi gli oggetti sono uguali . Quindi dovrebbe memorizzare entrambi i valori corrispondenti a "abused" e "horsemints" al bucket 1 (1069518484 % 3) .
Ora la mappa hash assomiglia a -
Array Index 0 –
Array Index 1 - LinkedIst (“ahhan” , “Manmohan Singh” , “guess what”)
Array Index 2 – LinkedList (“way”)
Array Index 3 –
Ora se qualche corpo cerca di trovare il valore per la chiave “horsemints”, java troverà rapidamente l'hashCode di esso , lo modulerà e inizierà a cercare il suo valore nella LinkedList corrispondente index 1. Quindi in questo modo non abbiamo bisogno di cercare tutti i 4 indici di array rendendo così più veloce l'accesso ai dati.
Ma , aspetta , un secondo . ci sono 3 valori in quell'indice di matrice corrispondente linkedList 1, come scopre quale era il valore per la chiave "horsemints" ?
In realtà ho mentito, quando ho detto che HashMap memorizza solo i valori in LinkedList .
Memorizza entrambe le coppie di valori chiave come voce della mappa. Quindi in realtà la mappa assomiglia a questo .
Array Index 0 –
Array Index 1 - LinkedIst (<”girl” => “ahhan”> , <” misused” => “Manmohan Singh”> , <”horsemints” => “guess what”>)
Array Index 2 – LinkedList (<”no” => “way”>)
Array Index 3 –
Ora puoi vedere Mentre attraversi la linkedList corrispondente per ArrayIndex1 confronta effettivamente la chiave di ogni voce a quella LinkedList a "horsemints" e quando ne trova uno restituisce solo il valore .
Spero che ti sia divertito durante la lettura:)